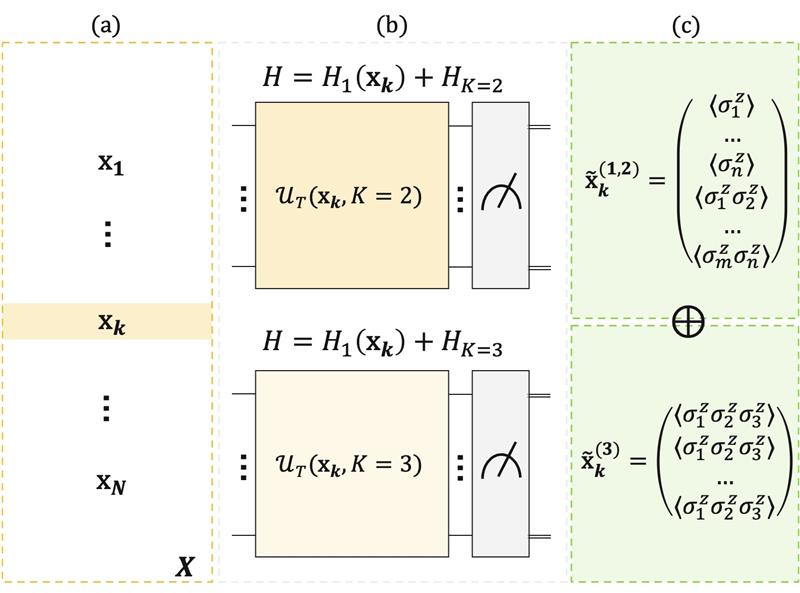
Figure 1: Each data sample (a molecule, an image, etc.) is encoded into a spin-glass Hamiltonian. (a) Tabular dataset X, from which samples and classical correlations are selected. (b) The extracted information from X is encoded into the local fields and higher-order coefficients of spin Hamiltonians differing in the order of interaction terms. (c) Local magnetizations and quantum correlations are measured from the two circuits and concatenated, yielding the quantum-extracted features.
Digitized Counterdiabatic Quantum Feature Extraction
In machine learning, we often need to turn raw data into meaningful features. This step, called feature extraction, helps models learn patterns and make better predictions. In our recent work, we explore how to use complex quantum dynamics to do that and significantly enhance machine learning tasks [1]. We apply our methods to realistic use cases, including breast tumor detection [2] and molecular toxicity prediction [3]. We use many-body spin Hamiltonians to generate complex and informative features from the provided data. These features arise from the dynamics of quantum spins, which evolve under an accelerated process called counterdiabatic quantum dynamics. After digitizing the final result, we obtained a quantum algorithm that can run on advanced IBM quantum processors. Therefore, the name of our method is “Digitized Counterdiabatic Quantum Feature Extraction”.
How it works
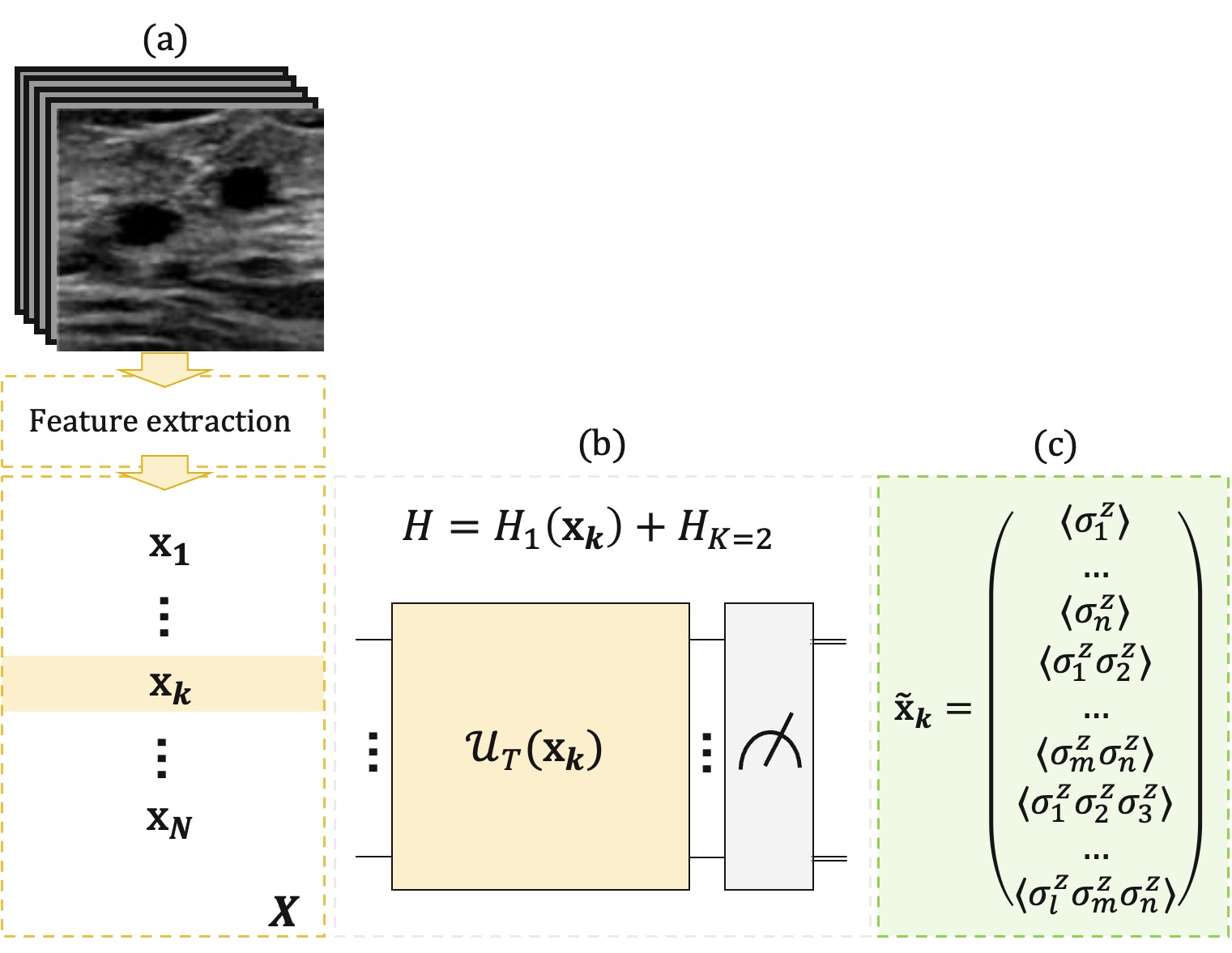
Each data sample, which can be a molecule, an image, or similar, is encoded into a spin-glass Hamiltonian. We do that by mapping both individual values and their statistical correlations onto the coupling strengths among quantum spins. After that, we let the system evolve using a counterdiabatic quantum dynamics in the impulse regime, implemented digitally on IBM’s Heron r2 156-qubit processor (ibm_kingston). Finally, we perform suitable measurements to get local magnetizations and higher-order correlations, which become our quantum-extracted features.
Testing with two realistic use cases
We tested the approach on two different problems:
1. Molecular toxicity classification [2]
– predicting whether a molecule is toxic or not.
2. Breast tumor detection [3]
– classification from 224x224 ultrasound images.
For the molecules, we used circuits with both two-body and three-body interaction terms. For the images, we combined classical features (from FFT, Gabor filters, etc.) with quantum ones. Both cases used Gradient Boosting models for classification.
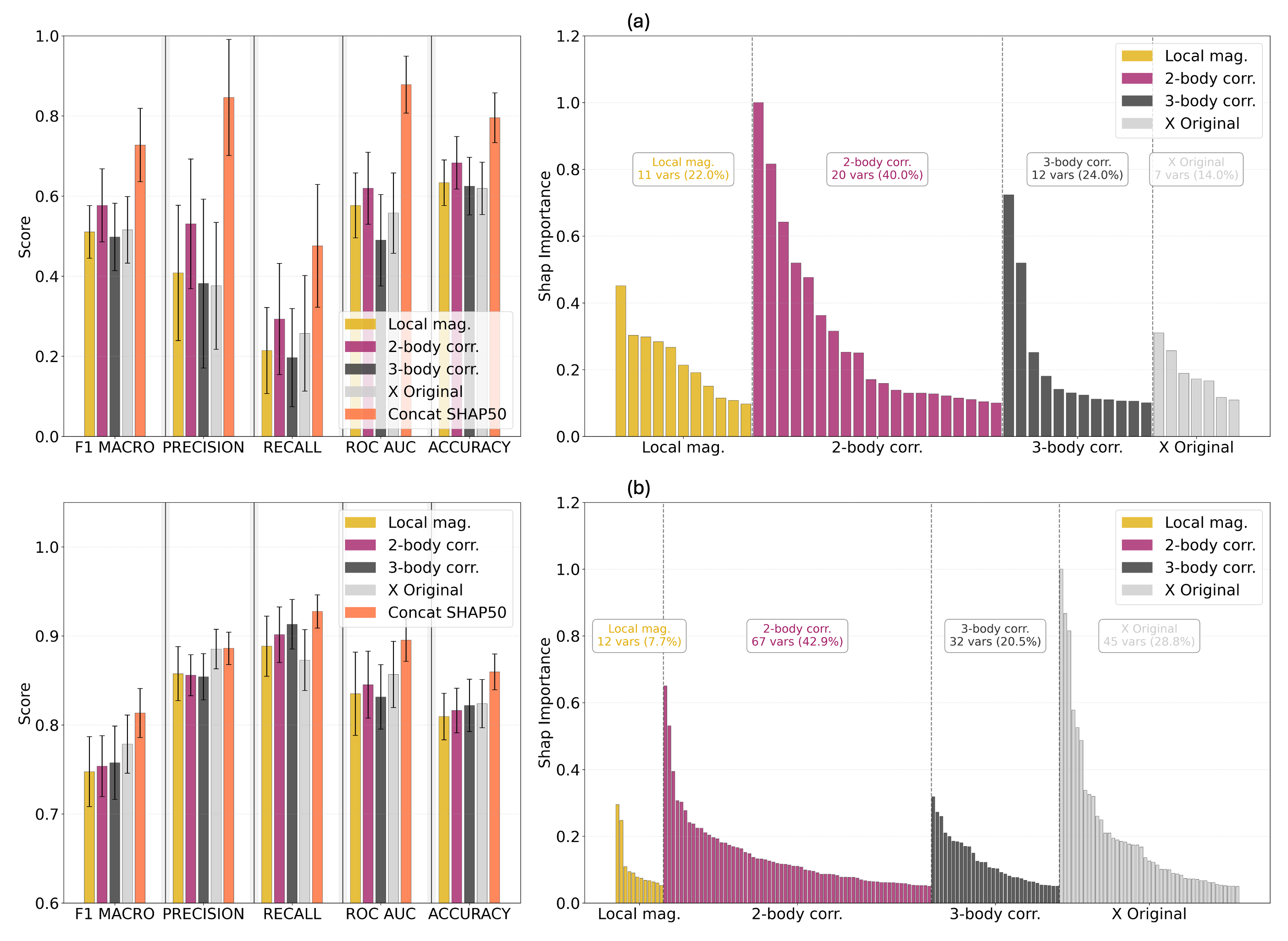
What we found
Quantum features clearly contributed to getting better results. When we combined them with classical ones, the accuracy neatly improved. As shown in Fig. 3, in the toxicity task, precision jumped by 121%, and most of the model’s essential features (based on SHAP analysis) come from quantum correlations. For breast tumor detection, the mean cross-validated AUC increased by 5.5% and beat well-established deep learning baselines, even though we only used 156 features. Table 1 shows that the best performance on the test dataset (Breast MNIST) is achieved using the SHAP-selected features. Specifically, the SVC (SHAP-selected) model attains an AUC of 0.937 and an accuracy of 0.876, improving Google AutoML Vision by approximately 2% in AUC and 1.7% in accuracy. This demonstrates the effectiveness of SHAP-based feature selection in enhancing the performance of traditional machine learning models.
| Method | AUC | Accuracy |
|---|---|---|
| SVC (SHAP-selected) | 0.937 | 0.876 |
| SVC (Original features) | 0.887 | 0.830 |
| GB (SHAP-selected) | 0.919 | 0.827 |
| GB (Original features) | 0.882 | 0.830 |
| ResNet-18 | 0.891 | 0.833 |
| ResNet-50 | 0.866 | 0.842 |
| Auto-sklearn | 0.836 | 0.803 |
| AutoKeras | 0.871 | 0.831 |
| Google AutoML Vision | 0.919 | 0.861 |
Why it matters
These results show that quantum computers can already produce results at the level of quantum advantage applied to industrial and medical machine learning problems, without the necessity of waiting for fault-tolerant quantum computers. By encoding correlations directly into local qubit terms and qubit interactions, we can extract richer, more structured features that classical preprocessing may easily miss. We have shown that today’s quantum processors, combined with codesigned quantum solutions provided by IBM and Kipu Quantum, respectively, can produce an early but real sign of quantum usefulness in data-driven applications.
References
[1] Simen, Anton, et al. Digitized Counterdiabatic Quantum Feature Extraction, 2025, https://arxiv.org/abs/2510.13807
[2] YANG, Jiancheng, et al. Medmnist v2-a large-scale lightweight benchmark for 2d and 3d biomedical image classification. Scientific Data, 2023, vol. 10, no 1, p. 41.
[3] Gül, Ş. & RAHIM, F. (2021). Toxicity [Dataset]. UCI Machine Learning Repository, https://doi.org/10.24432/C59313.