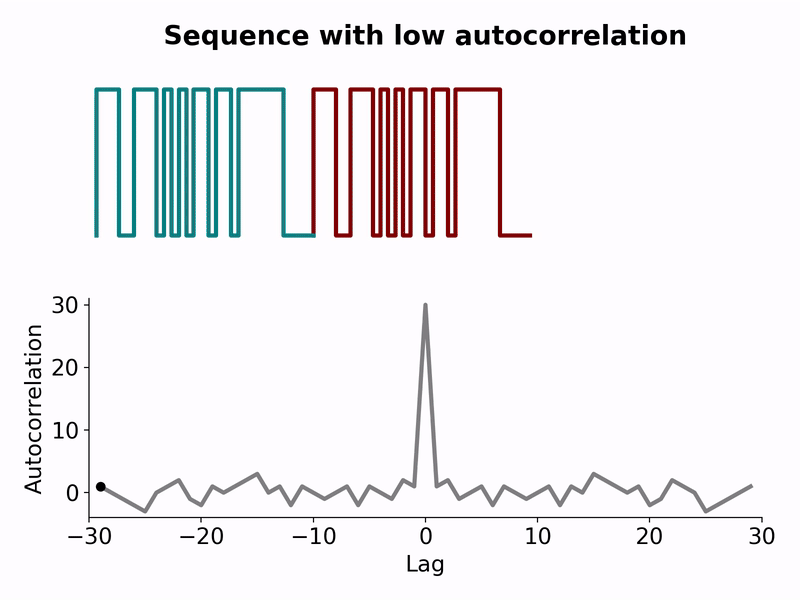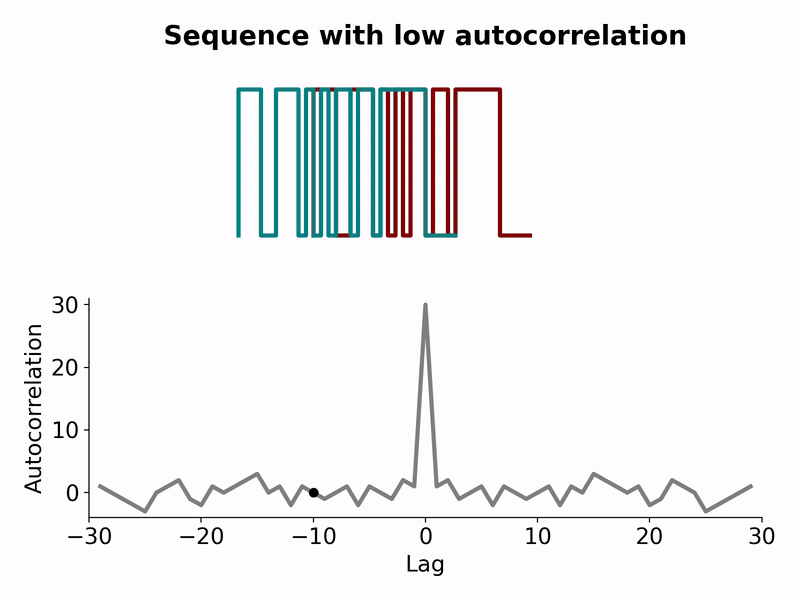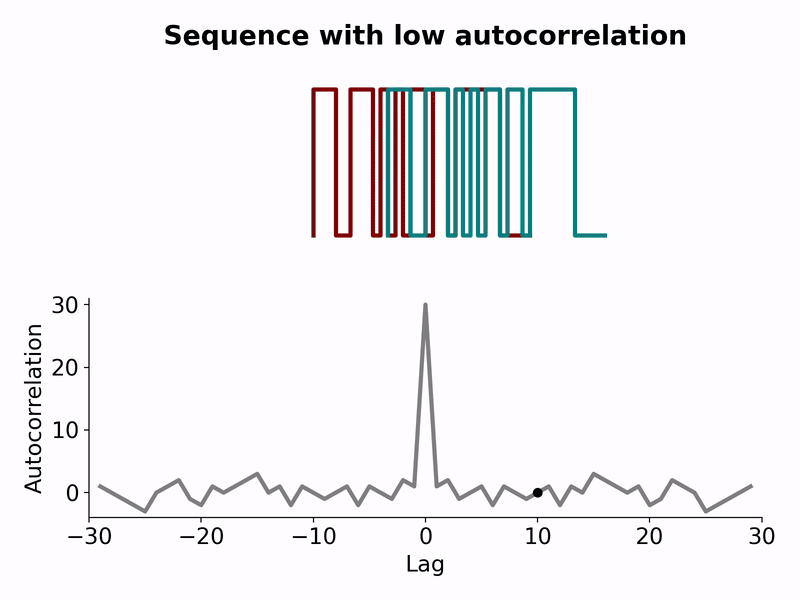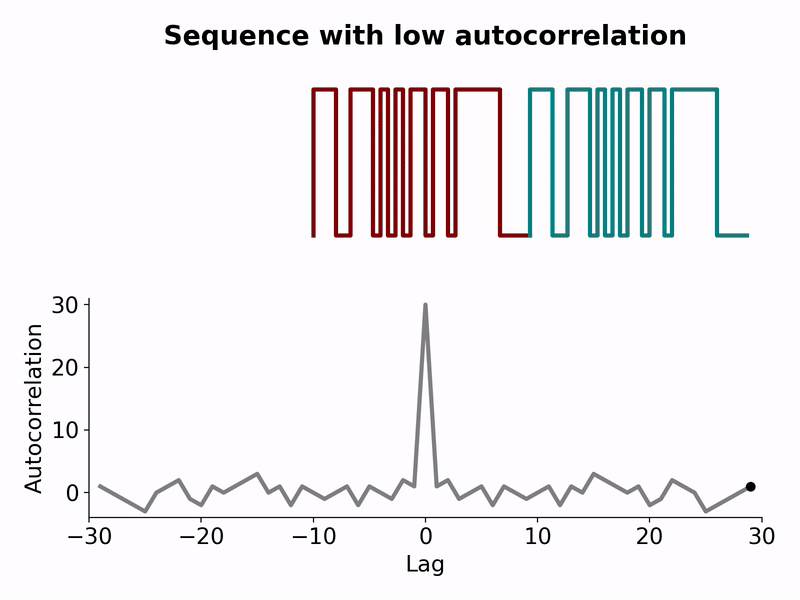
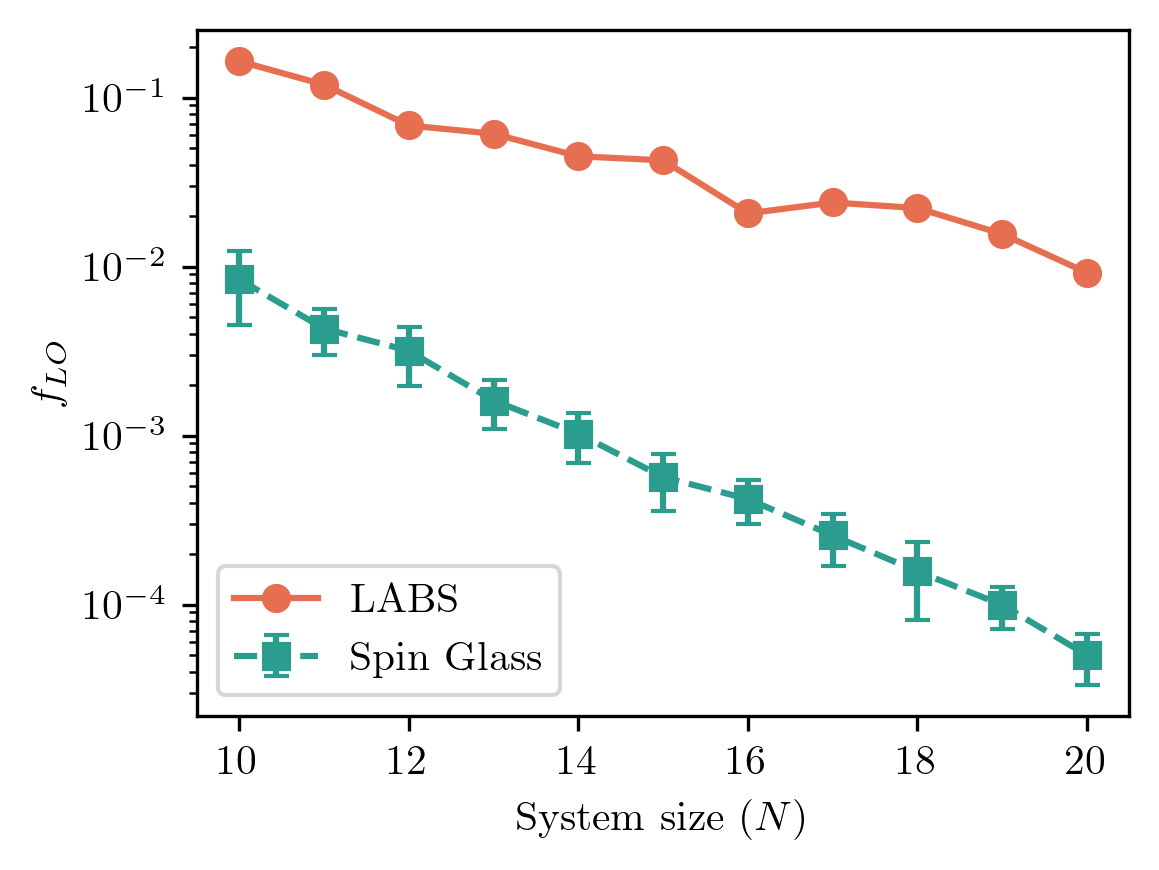
Figure 1. (Top) Example of a low autocorrelation binary sequence, which reduces interference and false detections, hence enhancing signal clarity and accuracy from the peak at zero lag. (Bottom) Density of single-flip local minima across different system sizes N for the LABS problem and the spin-glass SK case. This quantifies the number of configurations in which no single flip reduces the energy, compared to the total number of configurations. This supports why LABS is a more challenging problem than a common spin-glass benchmark.
Scaling Advantage with Quantum-Enhanced Memetic Tabu Search
In optimization, scaling is everything. Solvers eventually hit the wall where effort grows exponentially with problem size. Facing that wall, lowering the scaling base, is how we measure real computational progress.
At Kipu Quantum, in collaboration with NVIDIA, we have recently shown that hybrid quantum–classical optimization pipelines can accelerate purely classical ones [1]. Our latest work [2] introduces the Quantum-Enhanced Memetic Tabu Search (QE-MTS) for the Low-Autocorrelation Binary Sequence (LABS) problem. The result: a measurable scaling advantage for one of the hardest combinatorial benchmarks known.
The Low-Autocorrelation Binary Sequence (LABS) problem has long been a proving ground for optimization methods. It involves finding binary sequences that minimize unwanted correlations. In simple terms, building patterns that produce a sharp signal without echoes or interference. This challenge materializes in radar pulse design and communication protocols, where improvements in sequence quality translate into clearer signals and enhanced target detection, see Fig. 1 (top). In a previous blog, we have discussed about the LABS problem, its applications and why it is so demanding yet ideal for benchmarking [3]. Every sequence length defines a single, unique instance, forcing algorithms to confront a unique rugged landscape. When compared to other typical benchmarks, such as the spin-glass Sherrington-Kirkpatrick (SK) model, LABS exhibits more local minima, in other words, low non-optimal points where optimizers have a hard time escaping, see Fig. 1 (bottom).
A new type of hybrid providing scaling advantage
The idea behind QE-MTS is simple: let the quantum computer do what it is best at, generating low-energy samples via digitized counterdiabatic quantum optimization, and let the classical optimizer refine them. These quantum-informed candidates seed a population-based memetic tabu search, guiding it through the rugged energy landscape.
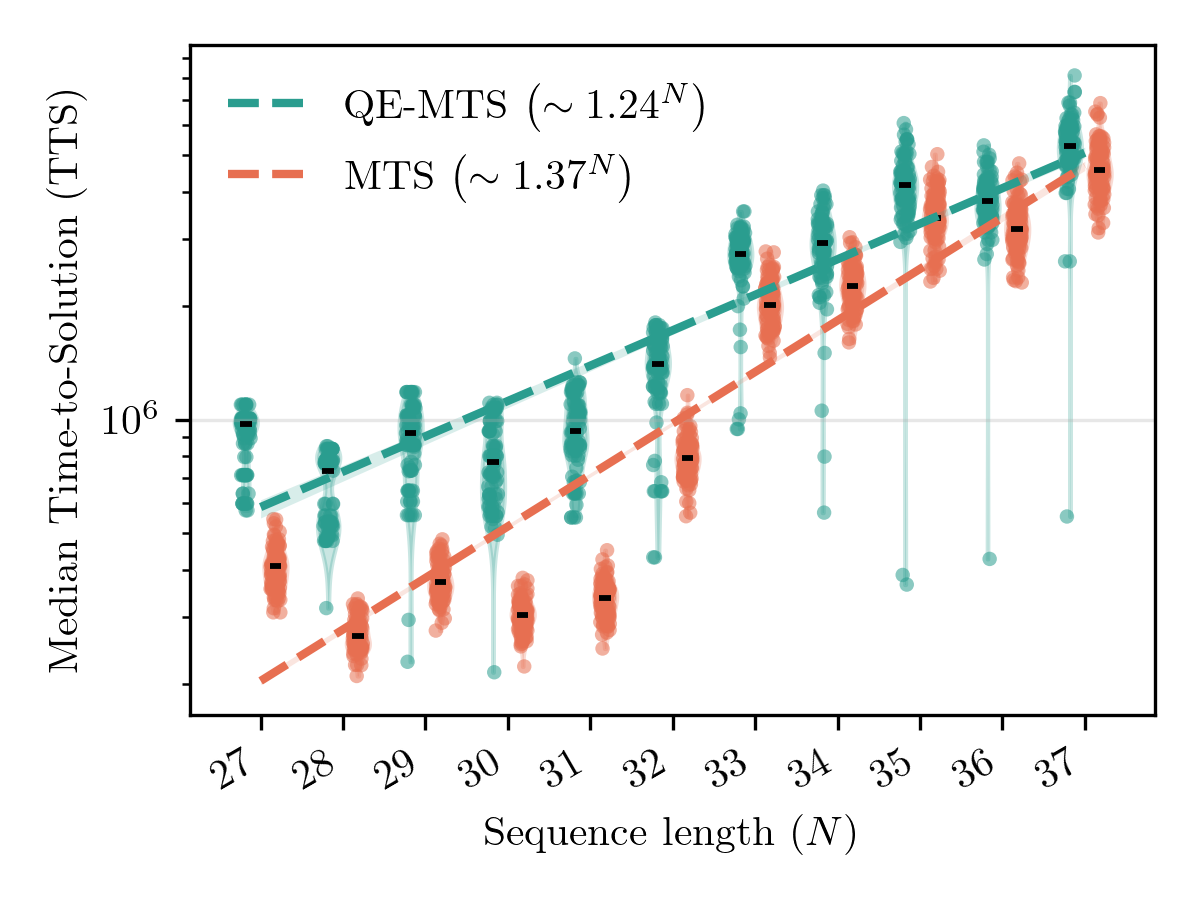
Across sequence lengths from 27 to 37, QE-MTS shows a typical scaling of O(1.24N), improving upon the O(1.34N) scaling of the best classical baseline. That difference may look small on paper, but in exponential growth, it is transformative. The analysis projects a crossover around N ≈ 47, where QE-MTS becomes faster than classical MTS for typical runs, widening its advantage as system size increases. In Fig. 2, we show the results and how the QE-MTS data approached the MTS one, implying a decreasing gap that eventually shows its full potential.
The quantum part of QE-MTS, digitized counterdiabatic quantum optimization, achieves this with a sixfold reduction in circuit depth compared to QAOA methods, keeping it suitable for early fault tolerant quantum computers.
Additional hardware and implementation details
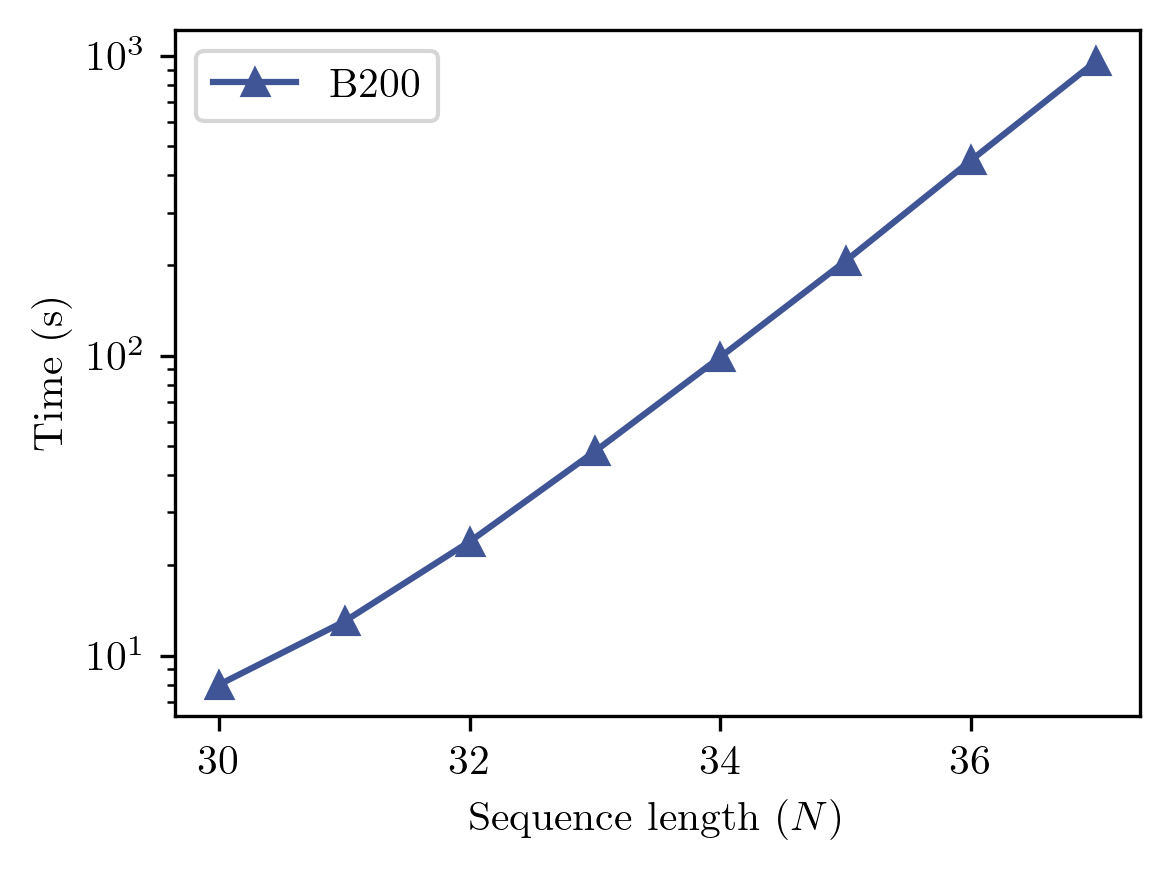
GPUs (Graphics Processing Units) are highly effective for simulating quantum circuits since they are designed to handle massive computations. Quantum circuit simulations involve manipulating large state vectors, whose size grows exponentially with the number of qubits. NVIDIA GPUs together with the CUDA-Q SDK [4] provide an intuitive and powerful tool to simulate these demanding quantum circuits. In our case, all quantum circuits were simulated on NVIDIA B200 GPUs using CUDA-Q, with up to N = 37 qubits via Amazon EC2 P6-b200.48xlarge instance. The runtimes can be seen in Fig. 3.
With QE-MTS, we see clear evidence that quantum enhancement can reshape classical scaling. This observation is not unique to LABS, but goes beyond other optimization problems, where hybrid sequential classical-quantum pipelines are leading. At Kipu Quantum, we believe this is how progress looks in the present, near and mid-term: smarter hybrids, measurable scaling gains, and tangible industrial impact.
Why this matters
With QE-MTS, we see clear evidence that quantum enhancement can reshape classical scaling. This observation is not unique to LABS, but goes beyond other optimization problems, where hybrid sequential classical-quantum pipelines are leading. At Kipu Quantum, we believe this is how progress looks in the present, near and mid-term: smarter hybrids, measurable scaling gains, and tangible industrial impact.
References
[1] Chandarana, P., Romero, S. V., Cadavid, A. G., Simen, A., Solano, E., & Hegade, N. N. (2025). Hybrid Sequential Quantum Computing. arXiv preprint arXiv:2510.05851.
[2] Cadavid, A. G., Chandarana, P., Romero, S. V., Trautmann, J., Solano, E., Patti, T. L., & Hegade, N. N. (2025). Scaling advantage with quantum-enhanced memetic tabu search for LABS arXiv preprint arXiv:2511.04553.
[3] Hegade, N. N., Cadavid, A. G. (2025). Quantum Optimization Benchmark Library: "The Intractable Decathlon” Kipu Quantum, Knowledge Hub, Blog.
[4] CUDA-Q Development Team, CUDA-Q (2025), https://nvidia.github.io/cuda-quantum/0.6.0/using/python.html accessed: 2025-07-14.